Gibbs Sampling to Estimate Genetic Parameters and Predict Breeding Values
The Gibbs sampling is an iterative method to generate solutions, and it falls under the Bayesian
statistics school of thought. A Bayesian approach assumes that every element of a model is a random
variable derived from a distribution function (e.g., uniform, normal, inverse chi-square). Also,
when one is estimating genetic parameters for a given trait before estimates are generated, it is
sometimes already known what the heritability of the trait should be based on previous estimates.
For example, fitness traits such as the number of piglets born alive should have a low heritability
(~5 to 15 %) compared to a trait such as the growth rate of a pig or the amount of backfat an animal
has at slaughter (30 to 50 %). The Bayesian approach allows for apriori information like this to be
included in the analysis.
The current function will be more for a simple animal model with a fixed intercept term and a
random vector of animal effects. Outlined below is the mixed linear model:
$$ \mathbf{y} = \mathbf{Xb} + \mathbf{Za} + \mathbf{e} $$
, where y is a vector of phenotypes, b is a vector of fixed effects, a is a
vector of random animal effects, e is a vector of random residuals, X is an incidence
matrix for the fixed effects and Z is an incidence matrix for the random effects. In the model
outlined above four classes of variables, referred to as \(\theta\), need to be estimated and include
b and a which pertains to the unique fixed and random effects along with the animal
(\(\sigma_a^2\)) and residual (\(\sigma_e^2\)) variance. For each random variable prior distributions
need to be assigned. For b, a uniform or normal prior distribution and for a a normal
prior distribution are commonly utilized. For the variances a scaled, inverted Chi-square distribution
with two hyperparameters, \(v\) and \(S^2\), with \(S^2\) being a prior estimate for the value
of the variance attributed to a particular parameter and v being the degrees of belief for the aprior value.
Although it may seem complicated at first, the Gibbs Sampler is relatively straight forward and is mainly
composed of conditional distributions of the variable versus all of the other variables. The conditional
distribution for each parameter within b and a and after all of the equations have been processed, new values
of the variances are calculated, and a new variance ratio is determined before beginning the next round. For
example, the conditional distribution of y given \(\theta\) (\(y|\theta\)) is outlined below:
$$ \mathbf{y} | \mathbf{b},\mathbf{a}, \sigma_a^2, \sigma_e^2 \sim N(\mathbf{Xb} + \mathbf{Za}, \mathbf{I}\sigma_e^2) $$
, or in other words, y is generated from a normal distribution with a mean of Xb + Za and a
variance of (\(\sigma_e^2\)). Outlined below are the conditional distributions for each random variable that
need to be estimated:
$$ \mathbf{b_i} | \mathbf{b_{-i}},\mathbf{a}, \sigma_a^2, \sigma_e^2 \sim N(\hat b_i, C_{i,i}^{-1}\sigma_e^2) $$
$$ \mathbf{a_i} | \mathbf{b},\mathbf{a_{-i}}, \sigma_a^2, \sigma_e^2 \sim N(\hat a_i, C_{i,i}^{-1}\sigma_e^2) $$
$$ \sigma_a^2 | \mathbf{b},\mathbf{a}, \sigma_e^2, y \sim \tilde v_a \tilde S_a^2 \chi_{\tilde v_a}^{-2}; $$
for \(\tilde v_a = q + v_a\), with q being the length of a and \(\tilde S_a^2 = (\mathbf{a'A^{-1}a} + v_aS_a^2) / \tilde v_a \).
This is where the prior belief of a given parameter enters when estimating variance components. Usually, q is much
larger than \(v_a\) and therefore, the data provides nearly all of the information about \(\sigma_a^2\).
$$ \sigma_e^2 | \mathbf{b},\mathbf{a}, \sigma_a^2, y \sim \tilde v_e \tilde S_e^2 \chi_{\tilde v_e}^{-2}; $$
for \(\tilde v_e = N + v_a\), with N being the number of observations and
\(\tilde S_e^2 = (\mathbf{e'e} + v_eS_e^2) / \tilde v_e \) and \(\mathbf{e} = \mathbf{y} - \mathbf{Xb} - \mathbf{Za}\).
All of these formulas previously outlined look rather complex and difficult to generate code for the Gibbs sampling
algorithm, but once one gets the hang of doing it for one variable it all will make more sense for the remaining
variables. The first step one has to do is generate the mixed model equations (e.g. \(k_a\) = \(\sigma_e^2\) / \(\sigma_a^2\))
which are outlined below:
As previously outlined the Gibbs sample works by generating estimates for each fixed and random effect and then a
random value is added to the solution based upon its conditional posterior distribution variance before proceeding to
the next level of that parameter or the next parameter. Outlined below is an example of how an estimate is generated
for each effect before adding a random value to the variable. The simplified example has an intercept and 5 random
animal effects.
Once one picks up on the general idea it is easy to make the method more complicated by adding more fixed effects
and/or random effects because all one has to be able to do is set up the mixed model equations. After one generates
new solutions with a random value added, the variance components are updated along with LHS pertaining to the random
effects. You have to update the LHS pertaining to the random effects because the ratio of residual to additive variance
will have changed across iterations.
GibbsSampler <- function(y,X,pedigree, iterations=1000, va=2, Sa=0.50, ve=2, Se=0.50)
{
message( "Begin Gibbs Sampling:")
message( " - First Set Up MME")
## First Generate Ainv ##
Ainv <- Ainv_Quaas1976(pedigree$animal,pedigree$sire,pedigree$dam)
## Figure out index for X and Z ##
indexX = c(1:ncol(X))
indexZ = c((ncol(X)+1):(nrow(pedigree)+ncol(X)))
## Now generate mixed model equations ##
LHS <- matrix(data=0,nrow=nrow(pedigree)+ncol(X),ncol=nrow(pedigree)+ncol(X))
## Random animal effects ##
Z <- matrix(data=0,nrow=nrow(pedigree),ncol=nrow(pedigree));
diag(Z) <- 1
## Build Each Part ##
LHS[indexX,indexX] <- t(X) %*% X
LHS[indexX,indexZ] <- LHS[indexZ,indexX] <- t(X) %*% Z
LHS[indexZ,indexZ] <- t(Z) %*% Z
## set up RHS ##
RHS <- matrix(data=0,nrow=nrow(pedigree)+ncol(X),1)
RHS[indexX,1] <- t(X) %*% y
RHS[indexZ,1] <- t(Z) %*% y
message( (paste(" - Dimension of LHS: ",nrow(LHS),"-",ncol(LHS),".",sep="")))
message( (paste(" - Dimension of RHS: ",nrow(RHS),"-",ncol(RHS),".",sep="")))
## Setup inverse chi square hyper-parameters ##
V_a = nrow(pedigree) + va; # sigma va in notes
V_e = length(y) + ve # sigma ve in notes
sigma_a = Sa;
sigma_e = Se;
## estimates for each parameter ##
theta <- c(rep(0.0,ncol(LHS)))
## Save samples at each iteration ##
samples <- matrix(data = 0,nrow=iterations,ncol=ncol(LHS)+2)
message( (" - Start Gibbs Sampler:"))
## Start Gibbs Sampler
for(iter in 1:iterations)
{
LHS_upd <- LHS;
LHS_upd[indexZ,indexZ] <- LHS_upd[indexZ,indexZ] + (Ainv * (sigma_e / sigma_a))
## update each theta ##
for (i in 1:length(theta))
{
mean <- (RHS[i,1] - sum(theta[-c(i)] * LHS_upd[i,-c(i)])) / LHS_upd[i,i]
var <- (sigma_e/LHS_upd[i,i])
theta[i] <- rnorm(1,mean,sqrt(var))
}
samples[iter,c(indexX,indexZ)] <- theta
## Calculate Residual Variance ##
e <- y - ((X %*% theta[indexX]) + Z %*% theta[indexZ])
sigma_e <- (sum(e*e) + (ve*Se)) / rchisq(1,(V_e), ncp = 0)
samples[iter,ncol(LHS)+1] <- sigma_e
## Calculate Additive Variance
sigma_a<-as.numeric(((theta[indexZ]%*%Ainv%*%theta[indexZ])+(va*Sa))/rchisq(1,(V_a),ncp=0))
samples[iter,ncol(LHS)+2] <- sigma_a
if(iter %% 10==0)
{
message((paste(" - ",iter,": Ve ",round(sigma_e,2),";Va ",round(sigma_a,2),sep="")))
}
}
message("Finished Gibbs Sampler")
return(samples)
}
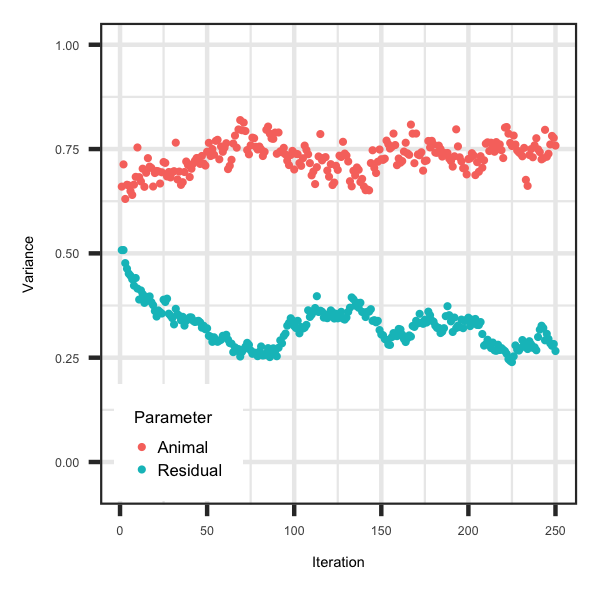
The following data files that contain pedigree and phenotype information can be utilized
to test the Gibbs sampler. The information was taken from the Geno-Diver software and the simulated additive and residual variance were 0.25
and 0.75, respectively. Outlined below is additive and residual variance across iterations.
- Sorenson D. and D. Gianola. Likelihood, Bayesian, and MCMC Methods in Quantitative Genetics.
- Wang C. S, J. J. Rutledge, D. Gianola. 1993. Marginal inferences about variance components in a mixed linear model using Gibbs sampling. Genet Sel Evol, 25:41-62.