Machine Learning Algorithms to Estimate Model Parameters
In the context of prediction, a linear model, although very simple, is a robust prediction
machine that can result in a similar or even better predictive ability than more complex models
such as random forest, support vector machines or neural networks. A linear regression model
prediction is summarized as: :
ŷ is the predicted value for a observation based on 'n' feature values and model parameters.
n is the total number of features or fixed effects based on previous pages.
xi is the feature value for the ith effect.
Θi is the model parameter for ith effect.
The following equation can be written in an alternative vectorized that is similar to many equations, where 'T'
represents the transpose of the matrix.
$$ \hat y = \theta^T X $$
When training a prediction model, the model parameters (e.g., Θ) is chosen so that the model "best" fits
the training data. The training dataset contains observations not contained within the sample where one wishes to
obtain predictions. In the context of animal breeding, one can think of the training set as older phenotyped animals,
and the test set as young animals lacking phenotypes. One such metric to define the best is the sum of the squared
differences between the prediction (e.g., Θx) and the actual value, also known as the Mean Square Error (MSE).
The MSE measures the average amount that the model's predictions vary from the actual values. The MSE is outlined
below and n refers to the number of observations:
$$ MSE = \frac{1}{n} \sum^n_{i=1} (\theta^T X - y)^2 $$
In the first year of graduate school in animal breeding, a statistics class will likely describe the ordinary least squares (OLS)
method to estimate the Θ values that minimize the MSE in a training set. In most cases, the OLS method of estimating the Θ
values is the preferred method, and as outlined below it is rather simple to obtain.
$$ \theta = (X^T X)^{-1} Xy $$
The cases where OLS becomes computationally intensive is when the number of features (n) becomes large and generating
the inverse of an n by n matrix (e.g., X transpose X) begins to be too computationally intensive. An alternative iterative
method that doesn't involve an inverse calculation is gradient descent. Gradient descent is an optimization algorithm that
minimizes MSE, or in the machine learning world, referred to as the cost function. Models with a high MSE are performing
poorly on the training dataset compared to models with lower MSE. The primary objective of the optimization algorithm is to
find the Θ values that result in the lowest possible MSE. The algorithm figures out the direction and rate at which
the Θ values are changing across iterations by taking the derivative of the MSE. The derivative tells us the direction
the Θ values should move along with how big of a step to take. Furthermore, the learning rate, that the user controls,
also impacts how big of a step to take. The derivative of the MSE is outlined below and n refers to the number of observations:
All three variations of the gradient descent algorithm use the same formula outlined above to determine gradient, which is
then multiplied by the learning rate and the result of this subtracted from the current Θ. Within each of the gradient
descent variants, this step is shown in red. The major difference between the different variations is the number of observations
it uses when calculating the gradient and they are described below:
Batch Gradient Descent: uses all of the observations.
Stochastic Gradient Descent: uses only one observation at a time.
Mini-Batch Gradient Descent: uses 'n' observation at a time.
For each method, it is essential to center and scale the variables before running the algorithm in order to ensure convergence.
For stochastic and mini-batch gradient descent it is important to shuffle the dataset to remove any inherent data trends. Furthermore,
one of the advantages of the stochastic and mini-batch versions is the path to the 'best' Θ is noisier compared to the batch
version. A noisier path may is important to allow the algorithm to potentially move out of a local minimum in order to reach the
global minima. Outlined below is R code for each version.
NormalEquations <- function(X,y)
{
message( "Utilizing Ordinary Least Squares (i.e. Normal Equations) to estimate theta values:")
message(paste( " - Number of Observations: ", nrow(X),".",sep=""))
message(paste( " - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## if full rank generate cholesky inverse and output theta ##
theta <- chol2inv(t(X) %*% X) %*% (t(X) %*% y)
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
return(list(Theta = theta))
}
BatchGradientDescent <- function(X, y, theta=c(), learning_rate=0.1, iterations=1000, outtheta_iter=FALSE)
{
message("Utilizing Batch Gradient Descent to estimate theta values:" )
message(paste(" - Learning Rate: ", learning_rate,".",sep=""))
message(paste(" - Number of Iterations: ", iterations,".",sep=""))
message(paste(" - Number of Observations: ", nrow(X),".",sep=""))
message(paste(" - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## figure out if theta was given if not then just fill with 0's ##
if(length(theta) == 0)
{
theta = rep(0.0,ncol(X))
}
if (length(theta) != ncol(X))
{
stop("Length of theta does not equal number of columns in X matrix!!")
}
theta_iter <- matrix(data = NA,ncol=ncol(X),nrow=iterations)
for(i in 1:iterations)
{
gradient = c((2/nrow(X)) * (t(X) %*% (X %*% theta - y)))
theta_iter[i, ] <- theta
theta = theta - (learning_rate * gradient)
}
## compute rmse: sum(yhat - y)*2 ##
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
if(outtheta_iter == FALSE)
{
return(list(Theta = theta))
}
if(outtheta_iter == TRUE)
{
return(list(Theta = theta, Theta_By_Iteration = theta_iter))
}
}
StochasticGradientDescent <- function(X, y, theta = c(), iterations=100, outtheta_iter = FALSE)
{
message("Utilizing Stochastic Gradient Descent to estimate theta values:")
message(paste(" - Number of Iterations: ", iterations,".",sep=""))
message(paste(" - Number of Observations: ", nrow(X),".",sep=""))
message(paste(" - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## figure out if theta was given if not then just fill with 0's ##
if(length(theta) == 0)
{
theta = rep(0.0,ncol(X))
}
if (length(theta) != ncol(X))
{
stop("Length of theta does not equal number of columns in X matrix!!")
}
theta_iter <- matrix(data = NA,ncol=ncol(X),nrow=(iterations+1))
theta_iter[1, ] <- theta
t0 = 5; t1 = 50 ## Learning Schedule Hyperparameters
for(i in 1:iterations)
{
for(j in 1:nrow(X))
{
randomindex = sample(nrow(X),1)
Xi <- X[randomindex, ]
yi <- y[randomindex]
gradient = c(2 * (Xi %*% (Xi %*% theta - yi)))
eta = t0 / (((i*nrow(X))+j) + t1)
theta = theta - (eta * gradient)
}
theta_iter[i+1, ] <- theta
}
## compute rmse: sum(yhat - y)*2 ##
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
if(outtheta_iter == FALSE)
{
return(list(Theta = theta))
}
if(outtheta_iter == TRUE)
{
return(list(Theta = theta, Theta_By_Iteration = theta_iter))
}
}
MiniGradientDescent <- function(X, y, theta = c(), iterations=100, minibatchsize = round(nrow(X)/4,0), outtheta_iter = FALSE)
{
message("Utilizing MiniBatch Gradient Descent to estimate theta values:")
message(paste(" - Number of Iterations: ", iterations,".",sep=""))
message(paste(" - Mini-batch Size: ", minibatchsize,".",sep=""))
message(paste(" - Number of Observations: ", nrow(X),".",sep=""))
message(paste(" - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## figure out if theta was given if not then just fill with 0's ##
if(length(theta) == 0)
{
theta = rep(0.0,ncol(X))
}
if (length(theta) != ncol(X))
{
stop("Length of theta does not equal number of columns in X matrix!!")
}
theta_iter <- matrix(data = NA,ncol=ncol(X),nrow=(iterations+1))
theta_iter[1, ] <- theta
## generate batch groups ##
groups <- matrix(data=NA,nrow=round(nrow(X)/ minibatchsize,0),ncol=2)
for(i in 1:round(nrow(X)/ minibatchsize,0))
{
groups[i,1] <- (minibatchsize*i)-(minibatchsize-1)
groups[i,2] <- minibatchsize*i
}
groups[nrow(groups),2] <- nrow(X)
t = 0 ## used in learning schedule ##
for(i in 1:iterations)
{
## first need to shuffle dataset in case there is some type of order in dataset ##
index <- sample(nrow(X))
Xshuf <- X[index, ]
yshuf <- y[index]
for(j in 1:nrow(groups))
{
t <- t + 1
Xi <- Xshuf[c(groups[j,1]:groups[j,2]), ]
yi <- yshuf[c(groups[j,1]:groups[j,2])]
gradient = c((2/length(c(groups[j,1]:groups[j,2]))) * (t(Xi) %*% (Xi %*% theta - yi)))
theta = theta - (learning_rate * gradient)
}
theta_iter[i+1, ] <- theta
}
## compute rmse: sum(yhat - y)*2 ##
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
if(outtheta_iter == FALSE)
{
return(list(Theta = theta))
}
if(outtheta_iter == TRUE)
{
return(list(Theta = theta, Theta_By_Iteration = theta_iter))
}
}
The following data files that contain X and
y can be utilized to test the algorithms.
The X matrix has already been centered and scaled. Outlined below is what the solutions are for different solving
methods. Look at the MSE across the different algorithms and the impact of learning rate and number of iterations on the MSE.
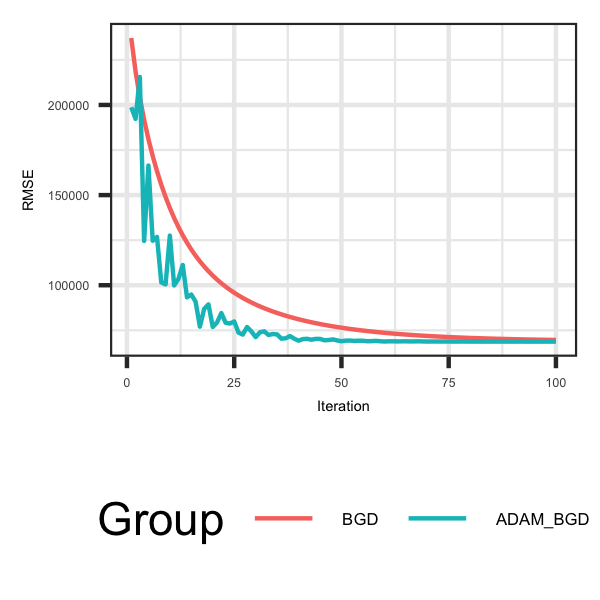
In the previous implementations of gradient descent the same learning rate is applied to all parameters and depending on the local
loss landscape the convergence may be slow. A method to tackle the second aspect is to incorporate a gradient accumulation or average
mechanism to utilize information from more than just the previous gradient, commonly referred to as 'momentum'. In the code outlined below,
the new parameters introduced 'm' and 'v', are exponentially decaying averages of past gradients. A number of different methods (add
momentum, AdaGrad, RMSprop) were generated to update the initial gradient descent, but the most common one is referred to as ADAM. The
code is outlined below and as outlined in the plots below the improvement in convergence is also shown.
ADAM_BatchGradientDescent <- function(X, y, theta = c(), alpha = 0.01, beta1 = 0.9, beta2 = 0.999, epsilon = 10^-8, iterations=100, outtheta_iter = FALSE)
{
message( "Utilizing Batch Gradient Descent with Adaptive Moment Estimation (ADAM) to estimate theta values:")
message(paste( " - Alpha: ", alpha,".",sep=""))
message(paste( " - Beta1: ", beta1,".",sep=""))
message(paste( " - Beta2: ", beta2,".",sep=""))
message(paste( " - Epsilon: ", epsilon,".",sep=""))
message(paste( " - Number of Iterations: ", iterations,".",sep=""))
message(paste( " - Number of Observations: ", nrow(X),".",sep=""))
message(paste( " - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## figure out if theta was given if not then just fill with 0's ##
if(length(theta) == 0)
{
theta = rep(0.0,ncol(X))
}
if (length(theta) != ncol(X))
{
stop("Length of theta does not equal number of columns in X matrix!!")
}
theta_iter <- matrix(data = NA,ncol=ncol(X),nrow=(iterations+1))
theta_iter[1, ] <- theta
m = c(0,rep(length(theta))); v = c(0,rep(length(theta)))
for(i in 1:iterations)
{
gradient = c((2/nrow(X)) * (t(X) %*% (X %*% theta - y)))
m = beta1 * m + (1.0 - beta1) * gradient
v = beta2 * v + (1.0 - beta2) * (gradient*gradient)
mhat = m / (1.0 - beta1**(i))
vhat = v / (1.0 - beta2**(i))
theta = theta - (((alpha) / ((sqrt(vhat) + epsilon)))+ mhat)
theta_iter[i, ] <- theta
}
## compute rmse: sum(yhat - y)*2 ##
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
if(outtheta_iter == FALSE)
{
return(list(Theta = theta))
}
if(outtheta_iter == TRUE)
{
return(list(Theta = theta, Theta_By_Iteration = theta_iter))
}
}
ADAM_MiniGradientDescent <- function(X, y, theta = c(), alpha = 0.01, beta1 = 0.9, beta2 = 0.999, epsilon = 10^-8, iterations=100,minibatchsize = round(nrow(X)/4,0), outtheta_iter = FALSE)
{
message( "Utilizing MiniBatch Gradient Descent with Adaptive Moment Estimation (ADAM) to estimate theta values:")
message(paste( " - Alpha: ", alpha,".",sep=""))
message(paste( " - Beta1: ", beta1,".",sep=""))
message(paste( " - Beta2: ", beta2,".",sep=""))
message(paste( " - Epsilon: ", epsilon,".",sep=""))
message(paste( " - Mini-batch Size: ", minibatchsize,".",sep=""))
message(paste( " - Number of Iterations: ", iterations,".",sep=""))
message(paste( " - Number of Observations: ", nrow(X),".",sep=""))
message(paste( " - Number of Features: ", ncol(X),".",sep=""))
## Check to see if is full rank and has an inverse ##
if((qr(t(X) %*% X)$rank) != ncol(X))
{
stop("X matrix is not full rank!!")
}
## figure out if theta was given if not then just fill with 0's ##
if(length(theta) == 0)
{
theta = rep(0.0,ncol(X))
}
if (length(theta) != ncol(X))
{
stop("Length of theta does not equal number of columns in X matrix!!")
}
theta_iter <- matrix(data = NA,ncol=ncol(X),nrow=(iterations+1))
theta_iter[1, ] <- theta
m = c(0,rep(length(theta))); v = c(0,rep(length(theta)))
## generate batch groups ##
groups <- matrix(data=NA,nrow=round(nrow(X)/ minibatchsize,0),ncol=2)
for(i in 1:round(nrow(X)/ minibatchsize,0))
{
groups[i,1] <- (minibatchsize*i)-(minibatchsize-1)
groups[i,2] <- minibatchsize*i
}
groups[nrow(groups),2] <- nrow(X)
for(i in 1:iterations)
{
## first need to shuffle dataset in case there is some type of order in dataset ##
index <- sample(nrow(X))
Xshuf <- X[index, ]
yshuf <- y[index]
## generate batch groups ##
for(j in 1:nrow(groups))
{
Xi <- Xshuf[c(groups[j,1]:groups[j,2]), ]
yi <- yshuf[c(groups[j,1]:groups[j,2])]
gradient = c((2/length(yi)) * (t(Xi) %*% (Xi %*% theta - yi)))
m = beta1 * m + (1.0 - beta1) * gradient
v = beta2 * v + (1.0 - beta2) * (gradient*gradient)
mhat = m / (1.0 - beta1**(j + (i-1)*nrow(groups)))
vhat = v / (1.0 - beta2**(j + (i-1)*nrow(groups)))
theta = theta - (((alpha) / ((sqrt(vhat) + epsilon)))+ mhat)
}
theta_iter[i, ] <- theta
}
## compute rmse: sum(yhat - y)*2 ##
message(paste("Root Mean Square Error: ",sqrt(sum(((X %*% theta) - y)^2) / nrow(X)),sep=""))
message("Finished!")
if(outtheta_iter == FALSE)
{
return(list(Theta = theta))
}
if(outtheta_iter == TRUE)
{
return(list(Theta = theta, Theta_By_Iteration = theta_iter))
}
}